Data Carpentry lesson to learn how to use command-line tools to perform …
Data Carpentry lesson to learn how to use command-line tools to perform quality control, align reads to a reference genome, and identify and visualize between-sample variation. A lot of genomics analysis is done using command-line tools for three reasons: 1) you will often be working with a large number of files, and working through the command-line rather than through a graphical user interface (GUI) allows you to automate repetitive tasks, 2) you will often need more compute power than is available on your personal computer, and connecting to and interacting with remote computers requires a command-line interface, and 3) you will often need to customize your analyses, and command-line tools often enable more customization than the corresponding GUI tools (if in fact a GUI tool even exists). In a previous lesson, you learned how to use the bash shell to interact with your computer through a command line interface. In this lesson, you will be applying this new knowledge to carry out a common genomics workflow - identifying variants among sequencing samples taken from multiple individuals within a population. We will be starting with a set of sequenced reads (.fastq files), performing some quality control steps, aligning those reads to a reference genome, and ending by identifying and visualizing variations among these samples. As you progress through this lesson, keep in mind that, even if you aren’t going to be doing this same workflow in your research, you will be learning some very important lessons about using command-line bioinformatic tools. What you learn here will enable you to use a variety of bioinformatic tools with confidence and greatly enhance your research efficiency and productivity.
Software Carpentry lesson that teaches how to use databases and SQL In …
Software Carpentry lesson that teaches how to use databases and SQL In the late 1920s and early 1930s, William Dyer, Frank Pabodie, and Valentina Roerich led expeditions to the Pole of Inaccessibility in the South Pacific, and then onward to Antarctica. Two years ago, their expeditions were found in a storage locker at Miskatonic University. We have scanned and OCR the data they contain, and we now want to store that information in a way that will make search and analysis easy. Three common options for storage are text files, spreadsheets, and databases. Text files are easiest to create, and work well with version control, but then we would have to build search and analysis tools ourselves. Spreadsheets are good for doing simple analyses, but they don’t handle large or complex data sets well. Databases, however, include powerful tools for search and analysis, and can handle large, complex data sets. These lessons will show how to use a database to explore the expeditions’ data.
The designing, collecting, analyzing, and reporting of psychological studies entail many choices …
The designing, collecting, analyzing, and reporting of psychological studies entail many choices that are often arbitrary. The opportunistic use of these so-called researcher degrees of freedom aimed at obtaining statistically significant results is problematic because it enhances the chances of false positive results and may inflate effect size estimates. In this review article, we present an extensive list of 34 degrees of freedom that researchers have in formulating hypotheses, and in designing, running, analyzing, and reporting of psychological research. The list can be used in research methods education, and as a checklist to assess the quality of preregistrations and to determine the potential for bias due to (arbitrary) choices in unregistered studies.
Sharing data and code are important components of reproducible research. Data sharing …
Sharing data and code are important components of reproducible research. Data sharing in research is widely discussed in the literature; however, there are no well-established evidence-based incentives that reward data sharing, nor randomized studies that demonstrate the effectiveness of data sharing policies at increasing data sharing. A simple incentive, such as an Open Data Badge, might provide the change needed to increase data sharing in health and medical research. This study was a parallel group randomized controlled trial (protocol registration: doi:10.17605/OSF.IO/PXWZQ) with two groups, control and intervention, with 80 research articles published in BMJ Open per group, with a total of 160 research articles. The intervention group received an email offer for an Open Data Badge if they shared their data along with their final publication and the control group received an email with no offer of a badge if they shared their data with their final publication. The primary outcome was the data sharing rate. Badges did not noticeably motivate researchers who published in BMJ Open to share their data; the odds of awarding badges were nearly equal in the intervention and control groups (odds ratio = 0.9, 95% CI [0.1, 9.0]). Data sharing rates were low in both groups, with just two datasets shared in each of the intervention and control groups. The global movement towards open science has made significant gains with the development of numerous data sharing policies and tools. What remains to be established is an effective incentive that motivates researchers to take up such tools to share their data.
A Data Carpentry curriculum for Economics is being developed by Dr. Miklos …
A Data Carpentry curriculum for Economics is being developed by Dr. Miklos Koren at Central European University. These materials are being piloted locally. Development for these lessons has been supported by a grant from the Sloan Foundation.
Software Carpentry lección para control de versiones con Git Para ilustrar el …
Software Carpentry lección para control de versiones con Git Para ilustrar el poder de Git y GitHub, usaremos la siguiente historia como un ejemplo motivador a través de esta lección. El Hombre Lobo y Drácula han sido contratados por Universal Missions para investigar si es posible enviar su próximo explorador planetario a Marte. Ellos quieren poder trabajar al mismo tiempo en los planes, pero ya han experimentado ciertos problemas anteriormente al hacer algo similar. Si se rotan por turnos entonces cada uno gastará mucho tiempo esperando a que el otro termine, pero si trabajan en sus propias copias e intercambian los cambios por email, las cosas se perderán, se sobreescribirán o se duplicarán. Un colega sugiere utilizar control de versiones para lidiar con el trabajo. El control de versiones es mejor que el intercambio de ficheros por email: Nada se pierde una vez que se incluye bajo control de versiones, a no ser que se haga un esfuerzo sustancial. Como se van guardando todas las versiones precedentes de los ficheros, siempre es posible volver atrás en el tiempo y ver exactamente quién escribió qué en un día en particular, o qué versión de un programa fue utilizada para generar un conjunto de resultados en particular. Como se tienen estos registros de quién hizo qué y en qué momento, es posible saber a quién preguntar si se tiene una pregunta en un momento posterior y, si es necesario, revertir el contenido a una versión anterior, de forma similar a como funciona el comando “deshacer” de los editores de texto. Cuando varias personas colaboran en el mismo proyecto, es posible pasar por alto o sobreescribir de manera accidental los cambios hechos por otra persona. El sistema de control de versiones notifica automáticamente a los usuarios cada vez que hay un conflicto entre el trabajo de una persona y la otra. Los equipos no son los únicos que se benefician del control de versiones: los investigadores independientes se pueden beneficiar en gran medida. Mantener un registro de qué ha cambiado, cuándo y por qué es extremadamente útil para todos los investigadores si alguna vez necesitan retomar el proyecto en un momento posterior (e.g. un año después, cuando se ha desvanecido el recuerdo de los detalles).
We have empirically assessed the distribution of published effect sizes and estimated …
We have empirically assessed the distribution of published effect sizes and estimated power by analyzing 26,841 statistical records from 3,801 cognitive neuroscience and psychology papers published recently. The reported median effect size was D = 0.93 (interquartile range: 0.64–1.46) for nominally statistically significant results and D = 0.24 (0.11–0.42) for nonsignificant results. Median power to detect small, medium, and large effects was 0.12, 0.44, and 0.73, reflecting no improvement through the past half-century. This is so because sample sizes have remained small. Assuming similar true effect sizes in both disciplines, power was lower in cognitive neuroscience than in psychology. Journal impact factors negatively correlated with power. Assuming a realistic range of prior probabilities for null hypotheses, false report probability is likely to exceed 50% for the whole literature. In light of our findings, the recently reported low replication success in psychology is realistic, and worse performance may be expected for cognitive neuroscience.
Scientists should be able to provide support for the absence of a …
Scientists should be able to provide support for the absence of a meaningful effect. Currently, researchers often incorrectly conclude an effect is absent based a nonsignificant result. A widely recommended approach within a frequentist framework is to test for equivalence. In equivalence tests, such as the two one-sided tests (TOST) procedure discussed in this article, an upper and lower equivalence bound is specified based on the smallest effect size of interest. The TOST procedure can be used to statistically reject the presence of effects large enough to be considered worthwhile. This practical primer with accompanying spreadsheet and R package enables psychologists to easily perform equivalence tests (and power analyses) by setting equivalence bounds based on standardized effect sizes and provides recommendations to prespecify equivalence bounds. Extending your statistical tool kit with equivalence tests is an easy way to improve your statistical and theoretical inferences.
The FOSTER portal is an e-learning platform that brings together the best …
The FOSTER portal is an e-learning platform that brings together the best training resources addressed to those who need to know more about Open Science, or need to develop strategies and skills for implementing Open Science practices in their daily workflows. Here you will find a growing collection of training materials. Many different users - from early-career researchers, to data managers, librarians, research administrators, and graduate schools - can benefit from the portal. In order to meet their needs, the existing materials will be extended from basic to more advanced-level resources. In addition, discipline-specific resources will be created.
Workshop overview for the Data Carpentry genomics curriculum. Data Carpentry’s aim is …
Workshop overview for the Data Carpentry genomics curriculum. Data Carpentry’s aim is to teach researchers basic concepts, skills, and tools for working with data so that they can get more done in less time, and with less pain. This workshop teaches data management and analysis for genomics research including: best practices for organization of bioinformatics projects and data, use of command-line utilities, use of command-line tools to analyze sequence quality and perform variant calling, and connecting to and using cloud computing. This workshop is designed to be taught over two full days of instruction. Please note that workshop materials for working with Genomics data in R are in “alpha” development. These lessons are available for review and for informal teaching experiences, but are not yet part of The Carpentries’ official lesson offerings. Interested in teaching these materials? We have an onboarding video and accompanying slides available to prepare Instructors to teach these lessons. After watching this video, please contact team@carpentries.org so that we can record your status as an onboarded Instructor. Instructors who have completed onboarding will be given priority status for teaching at centrally-organized Data Carpentry Genomics workshops.
Data Carpentry’s aim is to teach researchers basic concepts, skills, and tools …
Data Carpentry’s aim is to teach researchers basic concepts, skills, and tools for working with data so that they can get more done in less time, and with less pain. Interested in teaching these materials? We have an onboarding video available to prepare Instructors to teach these lessons. After watching this video, please contact team@carpentries.org so that we can record your status as an onboarded Instructor. Instructors who have completed onboarding will be given priority status for teaching at centrally-organized Data Carpentry Geospatial workshops.
This webinar outlines how to use the free Open Science Framework (OSF) …
This webinar outlines how to use the free Open Science Framework (OSF) as an Electronic Lab Notebook for personal work or private collaborations. Fundamental features we cover include how to record daily activity, how to store images or arbitrary data files, how to invite collaborators, how to view old versions of files, and how to connect all this usage to more complex structures that support the full work of a lab across multiple projects and experiments.
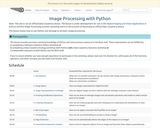
This lesson shows how to use Python and skimage to do basic …
This lesson shows how to use Python and skimage to do basic image processing. With support from an NSF iUSE grant, Dr. Tessa Durham Brooks and Dr. Mark Meysenburg at Doane College, Nebraska, USA have developed a curriculum for teaching image processing in Python. This lesson is currently being piloted at different institutions. This pilot phase will be followed by a clean-up phase to incorporate suggestions and feedback from the pilots into the lessons and to make the lessons teachable by the broader community. Development for these lessons has been supported by a grant from the Sloan Foundation.
Limiting the debilitating consequences of ageing is a major medical challenge of …
Limiting the debilitating consequences of ageing is a major medical challenge of our time. Robust pharmacological interventions that promote healthy ageing across diverse genetic backgrounds may engage conserved longevity pathways. Here we report results from the Caenorhabditis Intervention Testing Program in assessing longevity variation across 22 Caenorhabditis strains spanning 3 species, using multiple replicates collected across three independent laboratories. Reproducibility between test sites is high, whereas individual trial reproducibility is relatively low. Of ten pro-longevity chemicals tested, six significantly extend lifespan in at least one strain. Three reported dietary restriction mimetics are mainly effective across C. elegans strains, indicating species and strain-specific responses. In contrast, the amyloid dye ThioflavinT is both potent and robust across the strains. Our results highlight promising pharmacological leads and demonstrate the importance of assessing lifespans of discrete cohorts across repeat studies to capture biological variation in the search for reproducible ageing interventions.
Data Carpentry lesson to learn how to work with Amazon AWS cloud …
Data Carpentry lesson to learn how to work with Amazon AWS cloud computing and how to transfer data between your local computer and cloud resources. The cloud is a fancy name for the huge network of computers that host your favorite websites, stream movies, and shop online, but you can also harness all of that computing power for running analyses that would take days, weeks or even years on your local computer. In this lesson, you’ll learn about renting cloud services that fit your analytic needs, and how to interact with one of those services (AWS) via the command line.
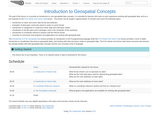
Data Carpentry lesson to understand data structures and common storage and transfer …
Data Carpentry lesson to understand data structures and common storage and transfer formats for spatial data. The goal of this lesson is to provide an introduction to core geospatial data concepts. It is intended for learners who have no prior experience working with geospatial data, and as a pre-requisite for the R for Raster and Vector Data lesson . This lesson can be taught in approximately 75 minutes and covers the following topics: Introduction to raster and vector data format and attributes Examples of data types commonly stored in raster vs vector format Introduction to categorical vs continuous raster data and multi-layer rasters Introduction to the file types and R packages used in the remainder of this workshop Introduction to coordinate reference systems and the PROJ4 format Overview of commonly used programs and applications for working with geospatial data The Introduction to R for Geospatial Data lesson provides an introduction to the R programming language while the R for Raster and Vector Data lesson provides a more in-depth introduction to visualization (focusing on geospatial data), and working with data structures unique to geospatial data. The R for Raster and Vector Data lesson assumes that learners are already familiar with both geospatial data concepts and the core concepts of the R language.
Data Carpentry lesson to open, work with, and plot vector and raster-format …
Data Carpentry lesson to open, work with, and plot vector and raster-format spatial data in R. The episodes in this lesson cover how to open, work with, and plot vector and raster-format spatial data in R. Additional topics include working with spatial metadata (extent and coordinate reference systems), reprojecting spatial data, and working with raster time series data.
This workshop introduces the basic concepts of Git version control. Whether you're …
This workshop introduces the basic concepts of Git version control. Whether you're new to version control or just need an explanation of Git and GitHub, this two hour tutorial will help you understand the concepts of distributed version control. Get to know basic Git concepts and GitHub workflows through step-by-step lessons. We'll even rewrite a bit of history, and touch on how to undo (almost) anything with Git. This is a class for users who are comfortable with a command-line interface.
This class is designed for first-time and longer-term users of Jupyter Notebooks, …
This class is designed for first-time and longer-term users of Jupyter Notebooks, a workspace for writing code. The class focuses on using Notebooks to facilitate sharing and publishing of script workflows. It aims to provide users with knowledge about shortcuts, plugins, and best practices for maximizing re-usability and shareability of Notebook contents.
No restrictions on your remixing, redistributing, or making derivative works. Give credit to the author, as required.
Your remixing, redistributing, or making derivatives works comes with some restrictions, including how it is shared.
Your redistributing comes with some restrictions. Do not remix or make derivative works.
Most restrictive license type. Prohibits most uses, sharing, and any changes.
Copyrighted materials, available under Fair Use and the TEACH Act for US-based educators, or other custom arrangements. Go to the resource provider to see their individual restrictions.